先进入网站,网址 快手官网,不知道的自己百度。
1、进入后登录自己的账号,然后点击进入主页
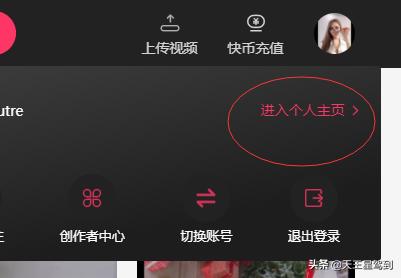

进入后左侧可以看到自己的关注人数,右侧是具体的关注账号,我们要获取的就是右侧的数据
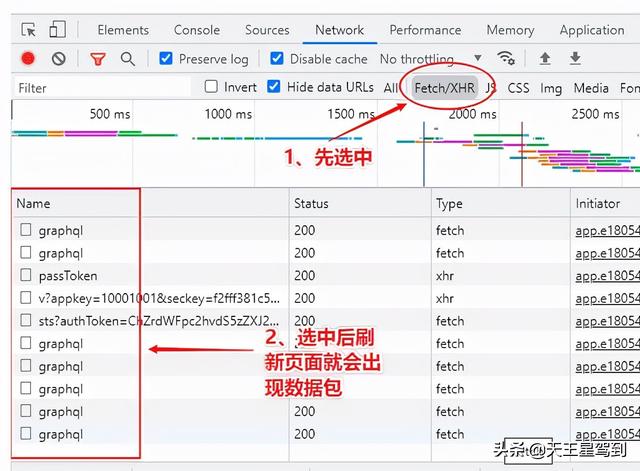
2、右键打开检测,切换到 network 窗口,再选中第三行工具栏的 Fetch/XHR ,然后刷新一下当前页面,可以看到数据包
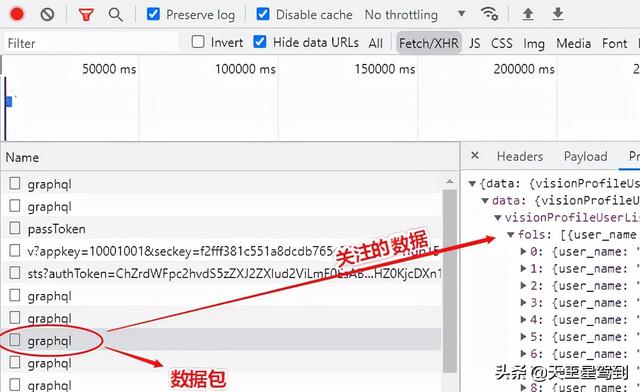
3、依次点击 graphql 数据包,找到需要的数据,这个列表就是我们需要的关注数据 visionProfileUserList
4、这个关注的数据获取到后,之后就是去找个人所有视频的数据啦啦啦
,随便打开一个人的主页,可以看到全部视频
OK,数据全部找到,接下来就是写代码了,话不多说直接上代码
有四个参数,你只需要填两个 一个是Cookie Cookie填的是登录后的,另一个是User-Agent
下边是完整代码
# coding:utf-8
import json
import os
import pprint
import re
import string
import sys
import time
import ctypes
import os
import platform
from zhon.hanzi import punctuation
import requests
import urllib3
urllib3.disable_warnings()
# 请求网页
def req_data(url, id, pcursor, ck, ua):
# 请求头
headers = {
'content-type': 'application/json',
'Cookie': ck,
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com/profile/' + id,
'User-Agent': ua
}
# 请求参数
data = {
'operationName': 'visionProfilePhotoList',
'query': "query visionProfilePhotoList($pcursor: String, $userId: String, $page: String, $webPageArea: "
"String) {\n visionProfilePhotoList(pcursor: $pcursor, userId: $userId, page: $page, webPageArea: "
"$webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n type\n author {\n "
" id\n name\n following\n headerUrl\n headerUrls {\n cdn\n "
" url\n __typename\n }\n __typename\n }\n tags {\n "
"type\n name\n __typename\n }\n photo {\n id\n duration\n "
" caption\n likeCount\n realLikeCount\n coverUrl\n coverUrls {\n "
" cdn\n url\n __typename\n }\n photoUrls {\n cdn\n "
" url\n __typename\n }\n photoUrl\n liked\n timestamp\n "
"expTag\n animatedCoverUrl\n stereoType\n videoRatio\n "
"profileUserTopPhoto\n __typename\n }\n canAddComment\n currentPcursor\n "
"llsid\n status\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n",
'variables': {'userId': id, 'pcursor': pcursor, 'page': 'profile'}
}
data = json.dumps(data)
data_json = requests.post(url=url, headers=headers, data=data, timeout=6.05).json()
# pprint.pprint(data_json)
return data_json
# 清洗文件名
def rep_char(chars):
eg_punctuation = string.punctuation
ch_punctuation = punctuation
# print("所有标点符号:", eg_punctuation, ch_punctuation)
for item1 in eg_punctuation:
chars = chars.replace(item1, '')
for item2 in ch_punctuation:
chars = chars.replace(item2, '')
chars = chars.replace(' ', '').replace('\n', '').replace('\xa0', '').replace('\r', '')
return chars
# 磁盘内存检查
def get_free_space():
folder = os.path.abspath(sys.path[0])
if platform.system() == 'Windows':
free_bytes = ctypes.c_ulonglong(0)
ctypes.windll.kernel32.GetDiskFreeSpaceExW(ctypes.c_wchar_p(folder), None, None, ctypes.pointer(free_bytes))
return free_bytes.value / 1024 / 1024 / 1024
else:
st = os.statvfs(folder)
return st.f_bavail * st.f_frsize / 1024 / 1024
# 保存数据
def save(url, page, ck, ua, selfid):
except_lit = []
count = 0
idlist = get_all_ids(url, page, ck, ua, selfid)
for id in idlist:
count = count + 1
print(f'第{count}位关注:{id} 全部视频下载中...')
num = 0
# 循环下载视频,直到 page == 'no_more'
while page != 'no_more':
time.sleep(1)
data = req_data(url, id, page, ck, ua)
# 获取翻页的参数
next_page_Pcursor = data['data']['visionProfilePhotoList']['pcursor']
page = next_page_Pcursor
print(next_page_Pcursor)
data_list = data['data']['visionProfilePhotoList']['feeds']
for item in data_list:
num = num + 1
video_name = item['photo']['caption']
video_url = item['photo']['photoUrl']
author = item['author']['name']
author = rep_char(author)
video_name = rep_char(video_name)
path = './video1'
if not os.path.exists(path + '/' + author + '/'):
os.makedirs(path + '/' + author + '/')
filepath = path + '/' + author + '/' + str(num) + '.' + video_name + '.mp4'
if os.path.exists(filepath):
print(f'{num}、 {video_name} >>> 已存在!!!')
# time.sleep(1)
continue
# 请求二进制视频数据
try:
video_content = requests.get(url=video_url, timeout=(3, 7)).content
except:
strss = f'{author}_{num}video_name:{video_url}'
except_lit.append(strss)
continue
with open(filepath, mode='wb') as f:
f.write(video_content)
print(f'{num}、 {video_name} >>> 下载完成!!!')
# 判断剩余容量是否充足
free_space = get_free_space()
if free_space <= 1:
break
# pcursor = page 这个变量的值必须为空,不用动他,它是换页的参数
page = ''
print(f'第{count}位关注:{id} 全部视频下载完成!!!')
with open('yc_info.txt', 'a') as f:
f.write(except_lit)
print('异常保存成功')
print(except_lit)
# 获取全部关注页面数据
def req_follow_data(url, pcursor, ck, ua, selfid):
# 请求头
headers = {
'content-type': 'application/json',
'Cookie': ck,
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com/profile/' + selfid,
'User-Agent': ua
}
# 请求参数
data = {
'operationName': 'visionProfileUserList',
'query': 'query visionProfileUserList($pcursor: String, $ftype: Int) {\n visionProfileUserList(pcursor: '
'$pcursor, ftype: $ftype) {\n result\n fols {\n user_name\n headurl\n '
'user_text\n isFollowing\n user_id\n __typename\n }\n hostName\n pcursor\n '
' __typename\n }\n}\n',
'variables': {'ftype': 1, 'pcursor': pcursor}
}
data = json.dumps(data)
follow_json = requests.post(url=url, headers=headers, data=data).json()
# pprint.pprint(follow_json)
return follow_json
# 获取全部关注的id
def get_all_ids(url, page, ck, ua, selfid):
id_list = []
num = sign = 0
# 循环保存id,直到 Pcursor == 'no_more'
while page != 'no_more':
time.sleep(1)
follow_data = req_follow_data(url, page, ck, ua, selfid)
# 获取翻页的参数
next_pcursor = follow_data['data']['visionProfileUserList']['pcursor']
page = next_pcursor
sign = sign + 1
print(f'第{sign}页:{next_pcursor}')
fols_list = follow_data['data']['visionProfileUserList']['fols']
for item in fols_list:
num = num + 1
user_name = item['user_name']
user_id = item['user_id']
id_list.append(user_id)
print(f'{num}、 {user_name}:{user_id} >>> ID获取成功!!!')
print(id_list)
print(id_list)
return id_list
if __name__ == '__main__':
link = 'https://www.kuaishou.com/graphql'
# pcursor这个变量的值开始必须为空,不用动他,它是换页的参数
# selfid 是自己账号网址的最后面那一串 例如 https://www.kuaishou.com/profile/3xkfgnn9hkacbwc selfid 就是 3xkfgnn9hkacbwc
selfid = ''
pcursor = ''
# ck ='' 引号中间填登录后的 Cookie 值
ck =''
# ua = '' 引号中间填 User-Agent
ua = ''
save(link, pcursor, ck, ua, selfid)
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 sumchina520@foxmail.com 举报,一经查实,本站将立刻删除。
如若转载,请注明出处:https://www.dasum.com/150212.html
如若转载,请注明出处:https://www.dasum.com/150212.html