题目
现有交易订单明细表,包含卖家id,买家id,订单日期三个字段,求3天内,10天内,15天内、30天内 不同卖家在这些时间段内不重复的客户数。
测试数据
假设统计日是2022年7月1日,构造6月份两个卖家的订单交易记录如下
CREATE TABLE wuqi_trade_seller_info lifecycle 1 AS
SELECT *
FROM values
('s1','b1','2022-06-30 00:00:00'), -- 3天内
('s1','b1','2022-06-23 00:00:00'), -- 10天内
('s1','b2','2022-06-21 00:00:00'),
('s1','b1','2022-06-18 00:00:00'), -- 15天内
('s1','b2','2022-06-16 00:00:00'),
('s1','b1','2022-06-10 00:00:00'), --30天内
('s2','b1','2022-06-23 00:00:00'), -- 10天内
('s2','b2','2022-06-10 00:00:00') --30天内
t(seller_id,buyer_id,buy_date)
;分析和思路
常规计算方法可以先针对每个窗口筛选出对应数据,并且通过group by 和 count distinct来实现。因为交易数据通常很大,而且计算的窗口可能也会很大,这种计算方式会有很大问题:重复多次读取数据,性能开销大;count distinct对内存压力大,可能影响任务的稳定性。
实现计算的方式也围绕着性能开销和内存来实现。直接给出解决步骤如下(性能分析看进阶分析)
- 通过CROSS JOIN 和Where语句将交易记录和对应窗口长度(window_size)进行关联生成多条记录,如一条纪录属于最近15天、30天则关联后生成两天记录
- 通过GROUP BY 卖家ID、买家ID、窗口长度window_size进行去重
- 通过GROUP By 卖家ID 和 sum、if 条件计算出不同window_size中去重卖家数。
实现
- 通过CROSS JOIN 和Where语句将交易记录和对应窗口长度(window_size)进行关联生成多条记录,如一条纪录属于最近15天、30天则关联后生成两天记录。
select * from(
SELECT * FROM wuqi_trade_seller_info
) t1 CROSS JOIN (
SELECT * FROM values(3),(10),(15),(30) t(window_size)
)t2
WHERE TO_CHAR(dateadd(to_date('20220701','yyyymmdd'),-window_size,'dd'),'yyyymmdd')
<= TO_CHAR(cast(buy_date as DATETIME ),'yyyymmdd')
AND '20220701' > TO_CHAR(cast(buy_date as DATETIME ),'yyyymmdd')处理后数据如下
seller_id buyer_id buy_date window_size
s1 b1 2022-06-30 00:00:00 3
s1 b1 2022-06-30 00:00:00 10
s1 b1 2022-06-30 00:00:00 15
s1 b1 2022-06-30 00:00:00 30
s1 b1 2022-06-23 00:00:00 10
s1 b1 2022-06-23 00:00:00 15
s1 b1 2022-06-23 00:00:00 30
s1 b2 2022-06-21 00:00:00 10
s1 b2 2022-06-21 00:00:00 15
s1 b2 2022-06-21 00:00:00 30
s1 b1 2022-06-18 00:00:00 15
s1 b1 2022-06-18 00:00:00 30
s1 b2 2022-06-16 00:00:00 15
s1 b2 2022-06-16 00:00:00 30
s1 b1 2022-06-10 00:00:00 30
s2 b1 2022-06-23 00:00:00 10
s2 b1 2022-06-23 00:00:00 15
s2 b1 2022-06-23 00:00:00 30
s2 b2 2022-06-10 00:00:00 30- 通过GROUP BY 卖家ID、买家ID、窗口长度window_size进行去重
代码如下
SELECT seller_id
,buyer_id
,window_size
FROM
(
select * from(
SELECT * FROM wuqi_trade_seller_info
) t1 CROSS JOIN (
SELECT * FROM values(3),(10),(15),(30) t(window_size)
)t2
WHERE TO_CHAR(dateadd(to_date('20220701','yyyymmdd'),-window_size,'dd'),'yyyymmdd')
<= TO_CHAR(cast(buy_date as DATETIME ),'yyyymmdd')
AND '20220701' > TO_CHAR(cast(buy_date as DATETIME ),'yyyymmdd')
)
GROUP BY seller_id
,buyer_id
,window_size生成结果如下
seller_id buyer_id window_size
s1 b1 3
s1 b1 10
s1 b1 15
s1 b1 30
s1 b2 10
s1 b2 15
s1 b2 30
s2 b1 10
s2 b1 15
s2 b1 30
s2 b2 30- 通过GROUP By 卖家ID 和 sum、if 条件计算出不同window_size中去重卖家数。
代码如下
select seller_id,
sum(if(window_size = 3 , 1, 0)) as buyer_num_ov3d,
sum(if(window_size = 10, 1, 0)) as buyer_num_ov10d,
sum(if(window_size = 15, 1, 0)) as buyer_num_ov15d,
sum(if(window_size = 30, 1, 0)) as buyer_num_ov30d
from
(
SELECT seller_id
,buyer_id
,window_size
FROM
(
select * from(
SELECT * FROM wuqi_trade_seller_info
) t1 CROSS JOIN (
SELECT * FROM values(3),(10),(15),(30) t(window_size)
)t2
WHERE TO_CHAR(dateadd(to_date('20220701','yyyymmdd'),-window_size,'dd'),'yyyymmdd')
<= TO_CHAR(cast(buy_date as DATETIME ),'yyyymmdd')
AND '20220701' > TO_CHAR(cast(buy_date as DATETIME ),'yyyymmdd')
)
GROUP BY seller_id
,buyer_id
,window_size
) group by seller_id
;最终结果如下:
|
seller_id |
buyer_num_ov3d |
buyer_num_ov10d |
buyer_num_ov15d |
buyer_num_ov30d |
|
s1 |
1 |
2 |
2 |
2 |
|
s2 |
0 |
1 |
1 |
2 |
进阶分析
- 性能分析:
完成计算任务只执行了一次SQL任务,只会读取一次数据; CROSS JOIN的右表只有几条记录不会产生性能影响;要关心的是通过CROSS JOIN 以后会产生多少数据呢?
假设数据是均匀分布的,且读取的数据只包含最近30天的数据,那么可以得出如下结论:
|
属于窗口 |
属于该窗口的数据占比 |
|
window_size=30 |
100% |
|
window_size=15 |
50% |
|
window_size=10 |
33.3% |
|
window_size=3 |
10% |
所以在第一步进行CROSS JOIN和where条件过滤后,数据生成的记录总数是100%+50%+33.3%+10%=193.3%,即产生1.93倍的数据量,相比分四次SQL任务执行读取4次数据至少是节省了一半的处理量。
- 稳定性分析
通过GROUP BY、sum if的方式避免了COUNT distinct 使用内存进行计数的方式,在任务稳定性上有更好的效果,也就是不容易因为内存不足导致任务失败。该任务的的主要复杂点在第一次Group by时(因为数据比较多)需要排序、去重。第二次GROUP BY时用第一次的排序结果即可,且数据量减少很多。
详细任务执行计划如下所示:
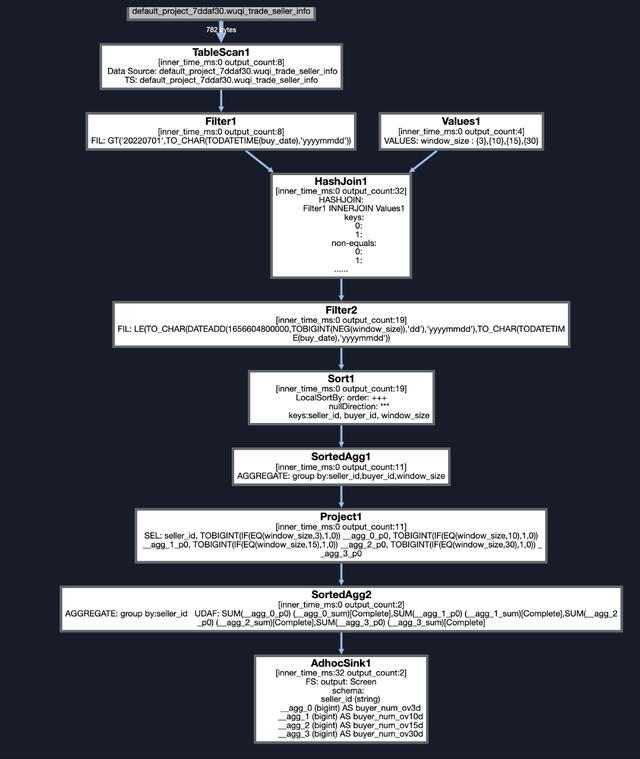

意义
业务上计算这种指标有什么意义呢?假设把买家换成IP地址,是不是就能找出不同地区的买家数量和对商品的热爱程度呢?进一步的如果打击黄牛,计算火车票设备地址号,交易记录集中出现在固定的设备上,是不是可以判定这设备可能是一个黄牛设备?
基于该场景的应用还有很多,评论区一起分享应用场景吧!

如若转载,请注明出处:https://www.dasum.com/93578.html