第一步:分析目标网页
观察该网页为异步还是同步加载,异步加载需去XHR获取数据包
获取数据包,观察有用的信息数据所在的位置
观察是post还是get请求
若是post请求,观察多个数据包的payload是否一致
补充关于payload的知识点:
若请求方法是post,参数用payload传,对应请求写法如下:
非scrapy,在发送请求时,应写为:
Requests.post(url = url, headers = headers, json = data)
#快手短视频的例子
url = 'https://www.kuaishou.com/graphql'
headers = {
'content-type': 'application/json',
'Cookie': 'clientid=3; did=web_f694eeea1a4227bf198e33436fbca07e; kpf=PC_WEB; kpn=KUAISHOU_VISION; ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjUxNjI3NDU1LjE2NDQ3MzQ1Mzk3MjAuMTU5MzA1Ng==|MS43NjQ1ODM2OTgyODY2OTgyLjUzMjEzMzU2LjE2NDQ3MzQ1Mzk3MjAuMTU5MzA1Nw==|0|graphql-server|webservice|false|NA',
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com/brilliant',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
data = {"operationName":"brilliantTypeDataQuery","variables":{"hotChannelId":"00","page":"brilliant","pcursor":"1"},"query":"fragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n id\n duration\n caption\n likeCount\n realLikeCount\n coverUrl\n photoUrl\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n __typename\n}\n\nfragment photoResult on PhotoResult {\n result\n llsid\n expTag\n serverExpTag\n pcursor\n feeds {\n ...feedContent\n __typename\n }\n webPageArea\n __typename\n}\n\nquery brilliantTypeDataQuery($pcursor: String, $hotChannelId: String, $page: String, $webPageArea: String) {\n brilliantTypeData(pcursor: $pcursor, hotChannelId: $hotChannelId, page: $page, webPageArea: $webPageArea) {\n ...photoResult\n __typename\n }\n}\n"}
# 传参要用json
response = requests.post(url=url,headers = headers,json=data)第二步:创建scrapy爬虫文件
创建爬虫项目scrapy startproject 爬虫项目名
cd 爬虫项目名文件夹
scrapy genspider 爬虫名 爬虫名.com
第三步:在爬虫项目名下的爬虫名.py内,建模

修改起始访问url和域名
class Mp4Spider(scrapy.Spider):
name = 'mp4'
allowed_domains = ['kuaishou.com'] # 域名
start_urls = ['https://www.kuaishou.com/graphql'] # 起始url重构起始请求
def start_requests(self):
headers = {
"content-type": "application/json",
"Cookie": "clientid=3; did=web_f694eeea1a4227bf198e33436fbca07e; ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjMxMTgyNzM3LjE2NDQ3Mjg5NzE5OTYuMTgyMDg5OTg=|MS43NjQ1ODM2OTgyODY2OTgyLjU5ODgxNzI3LjE2NDQ3Mjg5NzE5OTYuMTgyMDg5OTk=|0|graphql-server|webservice|false|NA; kpf=PC_WEB; kpn=KUAISHOU_VISION",
"Host": "www.kuaishou.com",
"Origin": "https://www.kuaishou.com",
"Referer": "https://www.kuaishou.com/brilliant",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36",
}
data = {"operationName": "brilliantTypeDataQuery",
"variables": {"hotChannelId": "00", "page": "brilliant", "pcursor": "1"},
"query": "fragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n id\n duration\n caption\n likeCount\n realLikeCount\n coverUrl\n photoUrl\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n __typename\n}\n\nfragment photoResult on PhotoResult {\n result\n llsid\n expTag\n serverExpTag\n pcursor\n feeds {\n ...feedContent\n __typename\n }\n webPageArea\n __typename\n}\n\nquery brilliantTypeDataQuery($pcursor: String, $hotChannelId: String, $page: String, $webPageArea: String) {\n brilliantTypeData(pcursor: $pcursor, hotChannelId: $hotChannelId, page: $page, webPageArea: $webPageArea) {\n ...photoResult\n __typename\n }\n}\n"}
# post请求,将payload用data接收
# for循环模拟翻页
for page in range(2):
# 构造post请求对象
yield scrapy.Request(
url=self.start_urls[0],
method='POST', # 修改请求方式为post
headers=headers,
dont_filter=True, # 不过滤相同的url
body=json.dumps(data) # 用body请求体接收data,json.dumps()将字典转为字符串,因为body的数据格式需要为字符串
)解析请求的数据
def parse(self, response):
"""
获取响应的json数据
:param response: 响应对象
:return:
"""
# 获取响应源码内容(str类型)
json_str_data = response.body.decode() # response.body的数据是二进制形式,要将二进制数据转为字符串
# print(json_str_data)
# 将字符串转为字典
json_dict_data = json.loads(json_str_data)
# print(json_dict_data)
# 获取所有数据的大字典
feeds_dict = json_dict_data['data']['brilliantTypeData']['feeds']
for feeds in feeds_dict:
item = {} # 构建传入管道的item的字典形式的数据
item['excel'] = 'excel数据' # 用于区分保存至excel的数据和保存为视频的数据
"""获取文字数据"""
# 作者id
author_id = feeds['author']['id']
item['author_id'] = author_id
# 作者名字
author_name = feeds['author']['name']
item['author_name'] = author_name
# 作品名字
video_name = feeds['photo']['caption']
item['video_name'] = video_name
# 作品点赞量
like = feeds['photo']['likeCount']
item['like'] = like
yield item
"""获取视频数据"""
# 作品名字
video_name = feeds['photo']['caption']
# 视频二进制数据
video_url = feeds['photo']['photoUrl']
# 构造视频下载地址
yield scrapy.Request(
url=video_url,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"},
dont_filter=True,
callback=self.parse_video_url, # 调用def parse_video_url方法解析获取视频二进制数据
meta={'video_name': video_name} #meta用于方法之间参数的传递,将video_name传入def parse_video_url方法
)定义解析获取视频二进制数据的方法
def parse_video_url(self,response):
item = {} # 构建传入管道的item的字典形式的数据
# 获取视频名称
video_name = response.meta['video_name'] # 利用response.meta方法获取video_name的值
item['video_name'] = video_name
# 获取视频二进制数据
video_byte = response.body # response.body用于获取二进制数据
item['video_byte'] = video_byte
yield item 第四步:将item数据传入管道,做数据保存
设置单独存储视频的文件夹,避免视频直接储存在scrapy文件下,显得很乱
import os, xlwt, xlrd
from xlutils.copy import copy
# 要导的包
class Mp4SpiderPipeline:
def open_spider(self, spider):
self.path = os.getcwd() + '/快手视频/'
if not os.path.exists(self.path):
os.mkdir(self.path)保存数据至excel模板,只需要修改第3,4,6,11,16,18行
def process_item(self, item, spider):
if 'excel' in item: # 通过之前在建模步骤设置的excel特殊键值来判断数据是否保存至excel
data = {
'快手短视频数据': [item['author_id'],item['author_name'],item['video_name'], item['like']]
} # data要以字典形式传入
os_mkdir_path = os.getcwd() + '/快手数据/'
# 判断这个路径是否存在,不存在就创建
if not os.path.exists(os_mkdir_path):
os.mkdir(os_mkdir_path)
# 判断excel表格是否存在 工作簿文件名称
os_excel_path = os_mkdir_path + '快手数据.xls'
if not os.path.exists(os_excel_path):
# 不存在,创建工作簿(也就是创建excel表格)
workbook = xlwt.Workbook(encoding='utf-8')
"""工作簿中创建新的sheet表""" # 设置表名
worksheet1 = workbook.add_sheet("快手短视频数据", cell_overwrite_ok=True)
"""设置sheet表的表头"""
sheet1_headers = ('作者id', '作者名字', '作品名字', '作品点赞量')
# 将表头写入工作簿
for header_num in range(0, len(sheet1_headers)):
# 设置表格长度
worksheet1.col(header_num).width = 2560 * 3
# 写入 行, 列, 内容
worksheet1.write(0, header_num, sheet1_headers[header_num])
# 循环结束,代表表头写入完成,保存工作簿
workbook.save(os_excel_path)
# 判断工作簿是否存在
if os.path.exists(os_excel_path):
# 打开工作簿
workbook = xlrd.open_workbook(os_excel_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_excel_path)
print(f"{item['video_name']}excel数据---------下载完成!!!")
数据保存为视频格式
else:
title = item['video_name']
data = item['video_byte']
with open(self.path + title + '.mp4', 'wb') as f: # 一定要加视频的后缀格式'.mp4'
f.write(data)
print(f'视频:{title}----------下载完成!!!')
return item要想使管道顺利运行,需在settings.py文件夹将以下几行代码激活
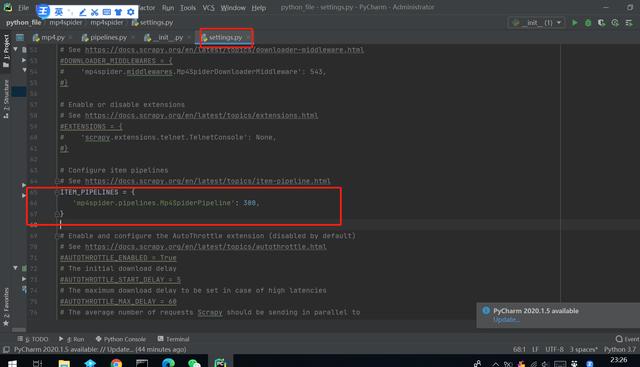
第五步:在__init__.py文件夹运行
运行之前,需在settings.py将以下几行代码注销
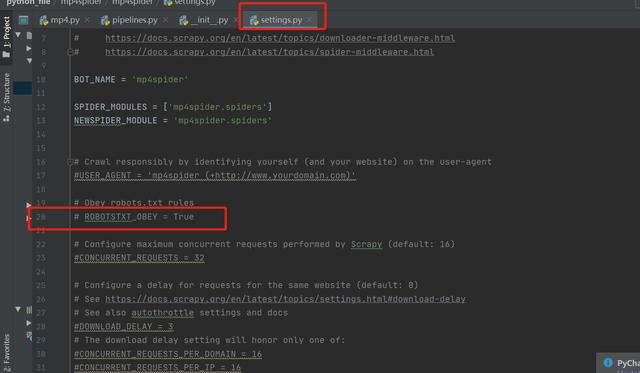
之后在__init__.py里输入代码如下
from scrapy import cmdline
cmdline.execute('scrapy crawl mp4 --nolog'.split(' '))
# cmdline.execute('scrapy crawl 爬虫名'.split(' ')),上面的mp4是我设置的爬虫名
# --nolog表示不打印红色的运行日志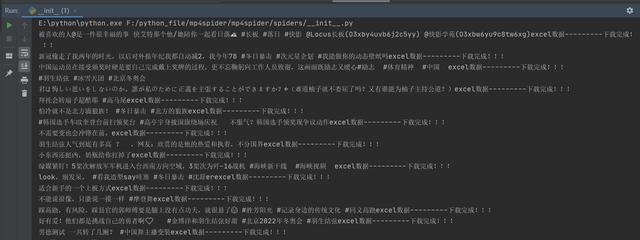
没有运行日志的run界面

本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 sumchina520@foxmail.com 举报,一经查实,本站将立刻删除。
如若转载,请注明出处:https://www.dasum.com/152341.html
如若转载,请注明出处:https://www.dasum.com/152341.html