来源:小桔灯网
作者:FLAME
为何需要把panel的TMB转换成WES水平的TMB,比较实用的一点是目前TMB国家参考品还是NCCL TMB室间质评都要求各厂家先把panel的TMB的转换成WES TMB,因为参考的答案都是WES TMB。因此,在此不再强调其重要性和意义。小编总结了2个可以参考的方法,当然各位可以根据自己的数据情况,制定更好的方案。
第一、 TMB国家参考品说明书提及的转换方法
Panel和WES的一致性评估采用简单线性回归。
首先,获取WES TMB(y)和panel TMB (x) 之间的线性回归曲线y=a+bx和决定系数,该步由R函数lm(http://www.endmemo.com/program/R/lm.php) 实现:
lm(y~x, data=your_data)。
在选定的显著性水平(参考品设定为0.1)下,该线性回归曲线的预测区间计算可由R函数predict实现:
predict(your_linear_model,interval=’predict’,level=1-alpha)。
若有另外的 panel TMB 数值需计算预测区间,可同样由R 函数predict实现:
predict(your_linear_model,newdata=your_panel_tmb,interval=’predict’, level=1-alpha)。
第二、 FOCR的文献中提及的转换方法
Friends of Cancer Research(FOCR)的precisionFDA组织的TMB lab的Phase2阶段(https://precision.fda.gov/challenges/18)完成的软件tmbLab,此软件只需要用户提供构建模型用的数据和想预测WES TMB的新的Panel TMB数据就可以计算出对应的WES TMB和指定的预测区间。
2.1下载地址
https://brb.nci.nih.gov/tmbLab/


图1:红框处为适用于linux系统的软件安装包
2.2安装
以linux系统上安装为例,选择图1中红框里的安装包进行下载后,使用R语言进行源码安装,脚本如下所示:
install.packages("tmbLab_1.0.0.tar.gz", repos = NULL, type="source")
2.3 软件使用
2.3.1 输入文件Model.WES.Panel.TMB.txt的准备
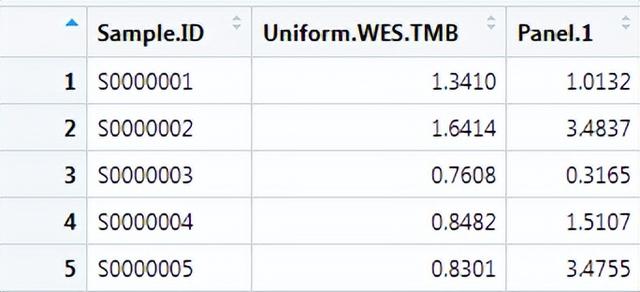
按照下表1准备构建gls线性回归模型使用的输入文件,Sample.ID为样本编号,Uniform.WES.TMB为该样本的WES TMB,Panel.1为该样本的Panel TMB。
表1:构建gls线性回归模型使用的输入文件格式要求
2.3.2 输入文件NewSample.Panel.TMB.txt的准备
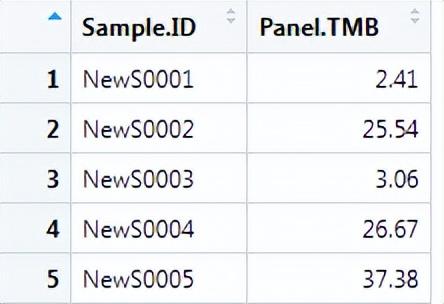
按照下表2准备新的Panel TMB的输入文件,Sample.ID为样本编号,Panel.TMB为该样本的 Panel TMB。
2.3.3 使用下面函数进行转换

说明:Calib.Interval参数为用户可以指定的预测区间,默认值为95%的预测区间,如果想计算90%,则设置为90即可。
2.4软件算法原理
我们检测到的TMB数值,其数值越大数据就越离散,即变异会越大。为了防止我们的模型过拟合,tmbLab软件采用gls线性回归模型,即线性回归系数的广义最小二乘(gls)估计。各TMB数值对模型的贡献取决于产生该数据的分布的变异,变异越大其权重就越小,因此此模型解决了过拟合的问题,从而增强其预测的准确性。
第三、 注意区分预测区间和置信区间
在使用上述2种方法时,小编在此特别强调我们计算的是预测区间,不是置信区间。置信区间(confidence interval estimate)是利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的平均值的估计区间。预测区间(prediction interval estimate)是利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的一个个别值的估计区间。预测区间的范围总是要比置信区间的范围要大的。

如若转载,请注明出处:https://www.dasum.com/105965.html